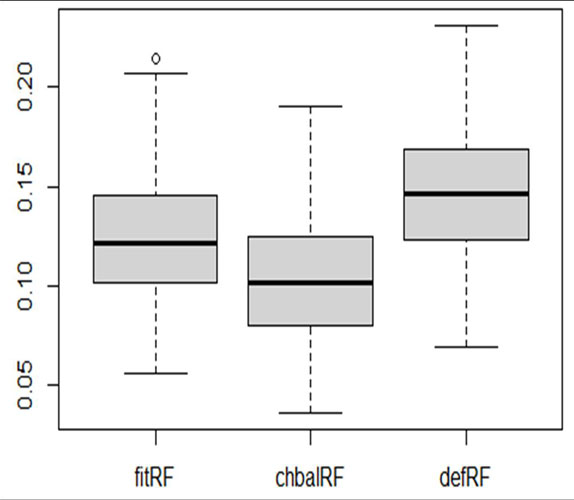
Recent studies have expanded the focus of machine learning methods like random forests beyond prediction. They have found utility in the area of causal inference by using it to estimate propensity scores. It has also been established in the literature that tuning the hyperparameter values of random forests can improve the estimates of causal treatment effects. We thus address the issue of getting the best out of random forest models by proposing to tune the random forest hyperparameters while maximizing covariate balance. We consider variants of tuning based on a model fit criterion and compare with tuning to chase covariate balance. In a simulation study and empirical application in two case studies, we studied the performance of different tuning implementations, relative to the random forest with default hyperparameters. We find that tuning to chase balance rather than model fit when estimating propensity scores induced better balance in the covariates and produced more accurate treatment effect estimates.