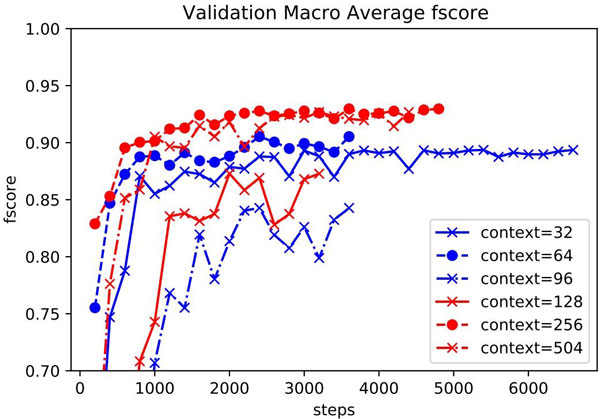
We propose TranSentCut, a sentence segmentation model for Thai based on the transformer architecture. Sentence segmentation for Thai is a problem because there is no end of sentence marker like in other languages. Existing methods make use of POS tags, which is not easy to label and must be done for every word in the data. This limits the the applicability and performance of sentence segmentation on open-domain text, because the only high-quality Thai corpus that has sentence boundary and POS labels was constructed mostly from academic articles. Our approach only uses raw text for training and the only labelling required is to separate each sentence into its own line in a text file. This makes new datasets much easier to construct. Comparison with existing methods show that our proposed model is competitive with the most recent state-of-the-art when evaluated on in-domain texts, and improved significantly over existing publicly available libraries when applied to out-ofdomain input texts.